Deep Dive
03 January 2021 / /
Our Trials and Tribulations with the Intel i40e Series
Our ISP network runs open source software as its BGP peering and transit edge, and we’ve written in considerable detail about those VyOS-powered routers.
We chose open source software as it afforded us many benefits, especially the flexibility it gives us to debug any problems that may arise. By becoming contributors to VyOS we no longer had to rely on a third-party vendor to rectify any deficiencies: we could actively work to improve the network operating system upon which we and our customers rely. Our depth of knowledge and operational experience can be shared with a wider community through our participation in the VyOS project.
Over the Christmas break we became aware of an edge case problem affecting our infrastructure. Since establishing a network ring around the UK we had found OSPFv3 to be less stable than before. This reached the height of its problems during the change-freeze: FRR’s ospf6d process would exit unexpectedly, causing instability in our internal IPv6 routing. At times this caused blackholing of IPv6 traffic to some destinations, requiring manual intervention. Our engineers were able to find configurations which were semi-stable where ospf6d would remain running in a non-resilient configuration, and only so long as there was not a topology change in the IPv6 network. Clearly a better solution was required.
Investigations led us to believe that a regression in FRRouting 7.3 had caused the problem, which meant the issue was affecting our routers in four key POPs: MA2, THW, THN, and IXN. Our VyOS router in MA1 was still running FRR 7.2 and was unaffected; and our VyOS router in AQL, having only been brought into production a couple of weeks earlier, was already running FRR 7.5. We soon found issues 6086 and 6378 from other network operators experiencing the same problems, and pull 6407 contributed by Cumulus Networks looked like a promising fix.
Having tested that an update to VyOS including FRR 7.5 was indeed a way forward, we decided to issue a series of emergency maintenance notices (2020-12-29, 2020-12-30, 2020-12-31) as a “breakfix” to ensure the stability of our IPv6 routing. These updates were carried out around 05:00 UTC, and progressed smoothly. IPv6 stability was achieved, and we closed the maintenances off.
By using off-the-shelf hardware to build those routers, we could choose equipment that meets the requirements for a particular network site: how many ports will we require, what level of traffic might this POP need to handle, and so on. This means that not all our routers run on the same hardware. As a result we have a mix of network interfaces in our routers using chipsets made by Intel, Broadcom, and QLogic. Within the Intel family of NICs we have some XL710 in our “flagship” routers in MA1 and MA2, AQL is based on 82599, and there are various i354/i210/other devices across the network. As a customer buying a network card you would expect a few key features:
- one or more ports to connect the network card to the network (e.g. QSFP, SFP+, RJ45, etc)
- some means of connecting the card to the server or router (e.g. PCIe)
- a driver for your operating system of choice, affording the ability to send and receive packets
Modern network cards include a plethora of additional functionality, not limited to:
- checksum calculation offload
- VLAN encapsulation/decapsulation
- underlay/overlay network offload (e.g. VXLAN, GENEVE)
- interrupt coalescing
- various tuneable ring-buffers
- network virtualisation (SR-IOV PF and VF support)
In the case of Intel’s XL710 NICs, Intel provides the i40e open source driver for Linux which can make use of the silicon on their network cards to accelerate network processing. We have several years of experience with the i40e driver, and have seen how it requires particularly careful care and feeding: the version of the Linux kernel you are running needs to match with a supported version of the i40e driver, which in turn needs to match with the version of the firmware (NVM and API) installed on the card, which determines which fancy features will be available. When architecting our routers we chose not to rely on any such fancy features, meaning we only had to constrain ourselves with the kernel/driver/firmware combination supported by VyOS.
Background
The maintenance to dekker.d.faelix.net, our transit and peering router in THW, had gone to plan on 29th December 2020. The only hitch (which had been anticipated) was that the IPv6 topology changes from reintroducing dekker into routing caused ospf6d to crash on some of the remaining FRR 7.3 routers. This was quickly worked around during the planned emergency maintenance window. The upgrade process started at 05:00 UTC, and was closed at 06:22 with a successful outcome.
When we updated our router in MA2, aebi.m.faelix.net, to a newer version of VyOS with FRR 7.5 on 30th December we also gained a newer version of the Linux kernel. In turn we unexpectedly gained a newer version of Intel’s i40e driver: 2.13.10. Soon after that mis-step we noticed the driver/firmware mismatch. We relied upon the DPDK i40e Driver page as a baseline for known-good combinations of driver and firmware, and so dutifully upgraded to firmware 8.00, updated the firmware and rebooted aebi during the maintenance window on the morning of 31st December. What we had not anticipated is that 2.13.10 — published by Intel as a stable version — would be a disaster. Some hours later, a little after 16:05 UTC on 31st December 2020, aebi spontaneously crashed.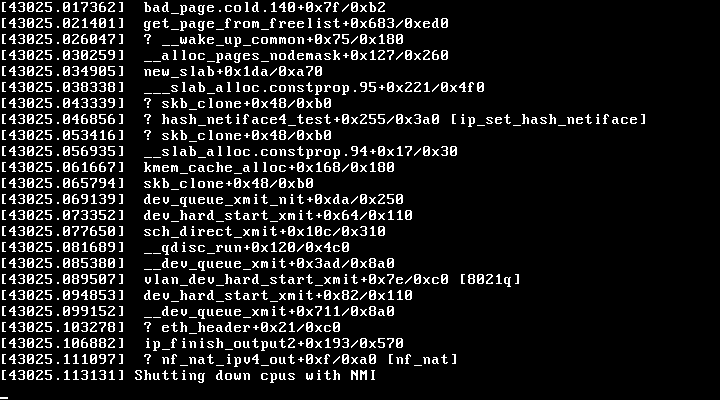
Incident Response
Unfortunately we were simultaneously hit by another bug, this time in FRR 7.2. Our router in MA1, bly.w.faelix.net, was sending traffic destined for LINX LON1 towards non-functioning aebi, causing traffic to be blackholed. In short the “FIB” did not match the “RIB”: the information learned from BGP and OSPF about the network topology (which had just changed significantly since aebi crashed) had not programmed the routing tables correctly. We could see that in our debugging during the incident. Here was the “best route” from bly to one of OVH’s subnets:
BGP routing table entry for 54.37.0.0/16
16276
195.66.225.6 (metric 440) from 46.227.204.4 (46.227.204.4)
Origin IGP, localpref 550, valid, internal, best (Local Pref)
Community: 8714:65010 8714:65011 8714:65023 41495:5459 41495:64701
Last update: Tue Dec 29 06:14:24 2020
The path to 46.227.204.4 (our router connected to LINX LON1 in London) was as follows, taking interface eth3.1307 towards AQL:
vyos@bly.w.faelix.net:~$ show ip route 46.227.204.4
Routing entry for 46.227.204.4/32
Known via "bgp", distance 200, metric 0
Last update 00:17:32 ago
46.227.204.4 (recursive)
46.227.203.220, via eth3.1307
Routing entry for 46.227.204.4/32
Known via "ospf", distance 110, metric 440, best
Last update 00:17:32 ago
* 46.227.203.220, via eth3.1307
However, the kernel was using a different link entirely — one towards the unresponsive router via eth2.1304 towards MA2:
vyos@bly.w.faelix.net:~$ ip route get 54.37.0.0/16
54.37.0.0 via 46.227.200.243 dev eth2.1304 src 46.227.200.244 uid 1003
cache
Our engineers resolved this by resetting some internal BGP sessions, thus forcing FRR on bly to recompute the paths.
Once traffic was once more routing correctly (at 17:05 UTC on 31st December 2020), our incident response could wind down. After a period of monitoring the network for stability, we began problem management: determining the root cause so as to eliminate the underlying issues.
Problem Management
Looking through the traceback in the kernel panic our lines of investigation were:
8021q— possibly a bug in VLAN tagging? maybe an acceleration function in the new driver?nf_nat_ipv4_out— our BGP edge routers do not perform any network address translation, but perhaps nftables in the newer kernel was not able to handle our iptables-based BCP38 filtering?new_slabandget_page_from_freelist— the router has 16GB of RAM, the router couldn’t be running out of memory?
After some hours we found the most likely culprit, in the form of an email exchange between another X7-series user and one of Intel’s developers just one day earlier. Paraphrasing:
User: during a benchmark of our Ceph cluster a server had a kernel panic, which our own detailed debugging and kernel tracing (attached, along with other evidence including a workaround by disabling a particular acceleration feature of the driver) strongly suggests is the fault of the i40e driver
Intel: you’re running Dell hardware, so you need to go get support from Dell, don’t come to this open-source project and post an email asking us for help
User: thanks for replying so quickly, this is an Intel-branded NIC (not a Dell rebadged one)
Intel: we don’t test Intel NICs in servers with AMD CPUs, so won’t be able to reproduce your bug to determine the cause
User: the previous version of Intel’s driver works fine, as does the Linux in-tree driver
Intel: oh yeah, this is a known issue… but I can’t tell you anything else, or when the fix will be available
This exchange was very useful for our investigation, but also disappointing. Frustratingly these NICs are among the only ones on the market supporting 4x10G in a single PCIe slot making them pretty much the only choice for high density SFP+ connectivity. This other report of a problem matched up with one of our suspected reasons behind aebi’s crash: out of memory allocating a slab (the partial kernel panic referencing new_slab and get_page_from_freelist). But the email thread also cemented the fact that Intel’s i40e drivers are still a source of problems years after this line of network cards was introduced. Worse, the tone of Intel’s response was to disavow responsibility in every way possible, including blaming the customer, before finally acknowledging it as a known fault. Another affected Intel NIC user has since remarked, “I’ve never seen anything like it.”
Thankfully we were able to engage the help of some of the VyOS core developers, even over the winter holiday period. We are very grateful to Christian Poessinger who issued us a build of VyOS 1.3 (including FRR 7.5) with the Linux in-kernel NIC drivers rather than the vendor’s own. We tested this thoroughly over the course of 1st January 2021, as we were expecting the community-developed and community-supported driver to have some shortfalls, perhaps lower performance efficiency. At least testing the alternative driver would confirm that our crash had been caused by the bug in Intel’s 2.13.10 driver.
After a period of 24 hours of testing we were convinced that the stock driver was not affected by this slab memory leaking issue, and we tentatively started bringing aebi back into service on 2nd January 2021, using the in-tree driver. We were surprised by the results in production: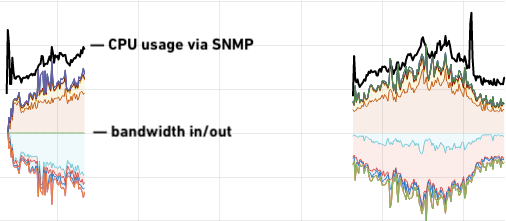
Far from being a performance regression, if anything we see the stock Linux driver is running at higher CPU efficiency for the same network throughput compared to Intel’s “optimised” driver. Looking back to earlier versions of VyOS and the Intel i40e driver, the improvement is significant: almost 60% reduction on CPU load. And, more importantly, the network is stable.
Conclusions
An unfortunate confluence of events and bugs came together to cause an outage which our network did not automatically route around. The Swiss cheese model of engineering analysis and risk management applies:
- Our testing was insufficient for the specific Intel hardware and driver used in
aebi: - We drew too heavily on our experience of running the
i40edrivers and hardware in production using published “known good” combinations of driver software and NIC firmware. - Positive experiences from testing on non-
i40eVyOS routers led us into a false sense of security, so we proceeded with a series of emergency maintenances. - Our legacy SNMP polling of VyOS did not give us the warning signs that slab leakage was occurring.
aebicrashed due to a poor driver implementation:- Insufficient quality assurance testing of the hardware and software prior to the vendor.
- Should have been picked up in their automated tests before a production release.
- Possibly Intel needs longer soak-testing or more detailed instrumentation.
blydid not reroute traffic correctly whenaebicrashed:- In spite of being engineered to route around failures, an unrelated software bug hampered correct network convergence.
On the positive side:
We were able to quickly identify the root causes. This is in no small part due to the open nature of the platform allowing our engineers to “deep dive” and identify the underlying problems.
Only one follow-on action remains (upgrading the software on
blyto eliminate the route convergence issue).Testing and production operation has shown an improvement in performance.
Newer monitoring functionality in VyOS gives us much more granular insights into our peering and transit estate, which will help us anticipate future problems.
Intel’s approach to NIC/driver support left us disillusioned, and will inform our choice of vendor when we upgrade our London network’s BGP peering and transit routers in 2021.
VyOS’ team was incredibly quick to respond, and accommodated an out-of-cycle patch for us to test, which actually resolved our problem.
Collaboration between open source projects and commercial companies can be a success (or failure) depending on the parties involved. By comparison we currently have three grave issues with other vendors which have been open for several weeks, despite being fully-commercial fully-supported hardware and software platforms